
Research
My research spans three closely interacting threads — Large Language Models & Safety, LLM Continual Learning, and AI for Science (AI4S). The common thread is how to train large parametric models so that they remain stable, knowledge-preserving, and physically faithful when the world (or the task stream, or the PDE) changes underneath them.
🧠 Large Language Models & Safety
I study post-training of large language and reasoning models — in particular, how the geometry of the optimizer shapes what a model learns, forgets, and refuses.
- Chain of Risk (arXiv 2026) — characterizes how chain-of-thought reasoning compounds safety failures in large reasoning models; introduces adaptive multi-principle steering as a step-wise mitigation. [paper]
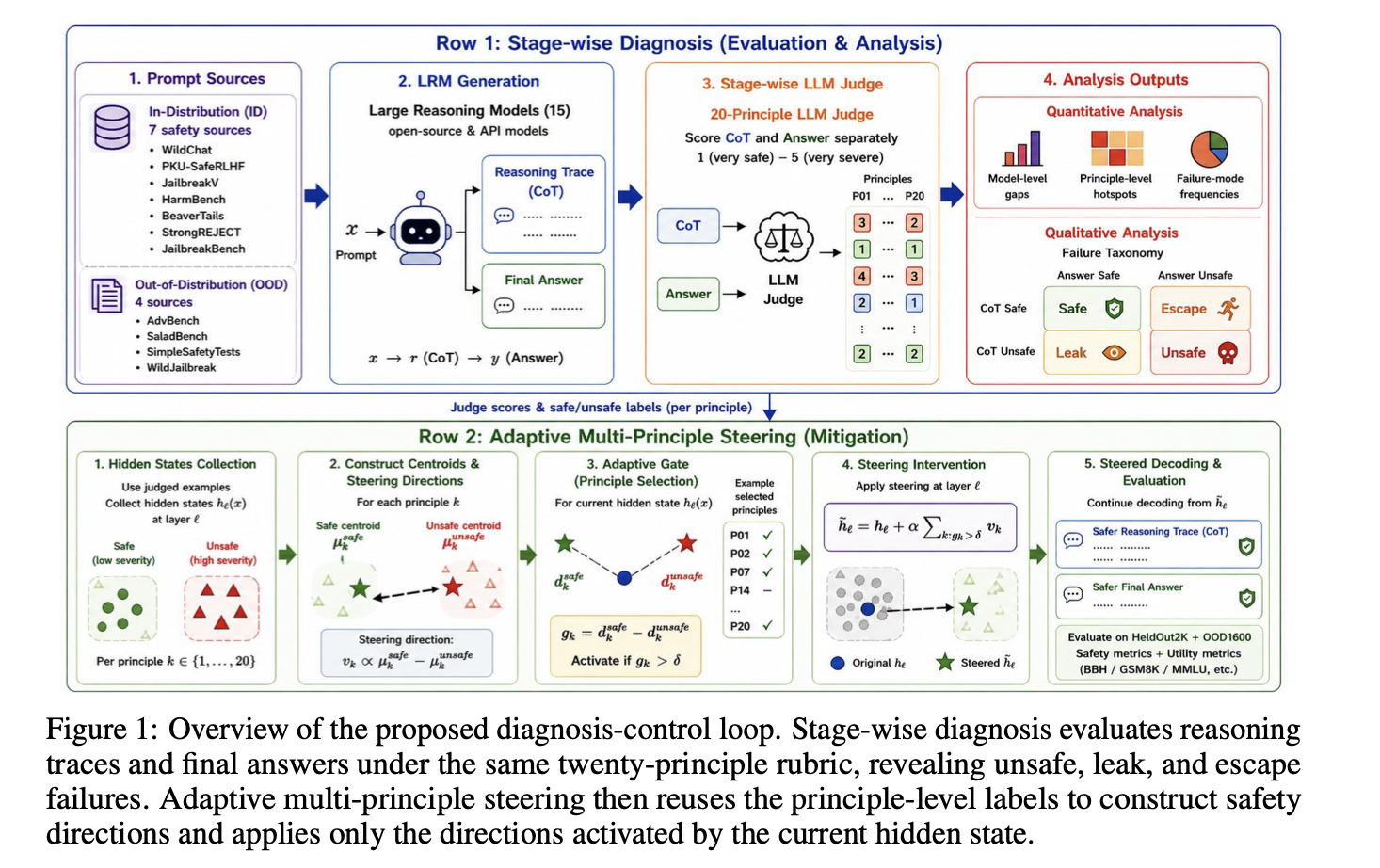
Open questions I care about. When does safety steering trade off against reasoning ability — and can we get both? How do unsafe intermediate steps interact with the spectral geometry of the model’s representations?
♻️ LLM Continual Learning
I design optimizers and training schemes that let pretrained LLMs keep learning — absorbing new tasks, domains, and skills while preserving what they already know. My approach combines spectral / orthogonal gradient projection with the matrix-aware preconditioning of modern LLM optimizers.
- Muon-OGD (arXiv 2026) — Muon-based spectral orthogonal gradient projection. Updates are restricted to spectral subspaces orthogonal to prior-task representations, giving forgetting-resistant adaptation without sacrificing Muon’s efficiency. [paper]
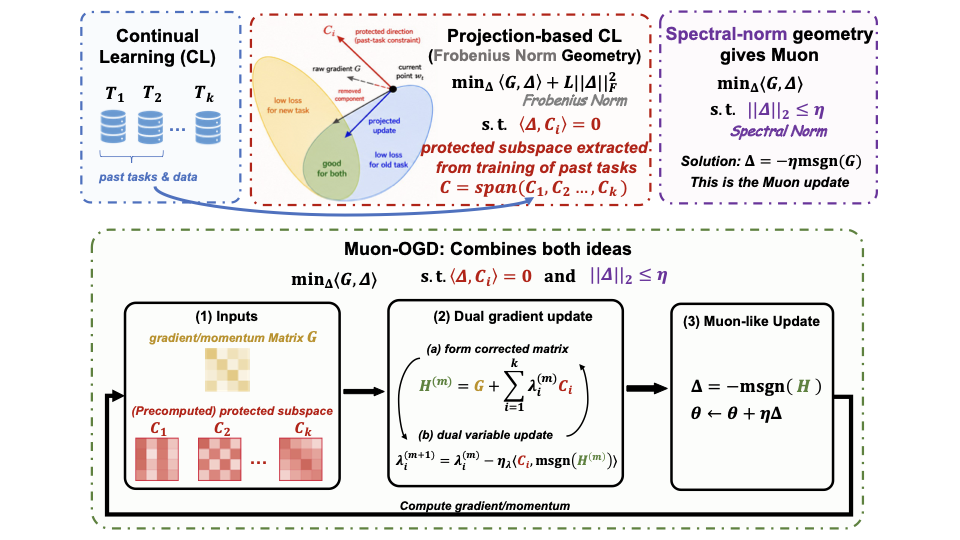
Open questions I care about. What is the right notion of “task subspace” for an LLM whose parameters are tied to language? Can spectral projections be made cheap enough to run at every step of post-training? How do we certify forgetting bounds without storing replay buffers?
🧪 AI for Science (AI4S)
On the scientific side, I build physics-informed and operator-learning methods for PDEs — including the nonlocal, high-dimensional, and stiff regimes where classical solvers struggle — together with the optimization machinery needed to train them.
- fPINN-DeepONet (JCP 2025) — operator learning for multi-term time-fractional mixed diffusion–wave equations. [paper]
- iPINNER / MoPINNEnKF (JCP 2025) — iterative PINN training coupled with ensemble Kalman filtering for calibrated parameter and state estimation. [paper]
- AdamFLIP (arXiv 2026) — adaptive feedback-linearization optimizer enforcing hard constraints in PINN training. [paper]

h(θ) = 0 step-by-step rather than via a soft penalty.- Muon with Spectral Guidance (arXiv 2026) — Muon augmented with spectrum-aware step sizes for stiff, multi-scale scientific-ML objectives. [paper]
- Neural-POD (arXiv 2026) — plug-and-play neural-operator framework for infinite-dimensional functional nonlinear proper orthogonal decomposition. [paper]
- Morphy-Net (CMAME 2026, accepted) — evolutionary multi-objective search with replica exchange for training physics-informed neural operators. [paper]
- NSGA-PINN (Algorithms 2023) — multi-objective NSGA-II training for PINNs; mitigates loss-balancing pathologies. [paper]
Open questions I care about. Can a single foundation operator model transfer across PDE families? How do we get rigorous a-posteriori error estimates for neural surrogates? What is the right inductive bias for fractional / nonlocal operators?
Co-authors
- Guang Lin — Associate Dean for Research; Moses Cobb Stevens Professor of Mathematics and Mechanical Engineering, Purdue University
- Na Li — Winokur Family Professor of Electrical Engineering and Applied Mathematics, Harvard University
- Changhong Mou — Assistant Professor, Department of Mathematics & Statistics, Utah State University
- Zhaopeng Hao — School of Mathematics, Southeast University, China
- Runyu (Cathy) Zhang — MIT
- Xiaomin Li — Harvard University
📄 A full list of papers, with categories aligned to the thrusts above, is on the Publications page. My most up-to-date record is on Google Scholar.